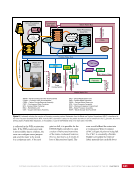
177 DAY IN THE LIFE: PREPARING FOR THE UNEXPECTED CHAPTER 10 real vehicle, this training teaches the flight controllers how to work as a team to solve problems often never anticipated, and how to work under pressure. While the flight controllers will learn the signature and responses of specific failures, the simulations also train them to approach a problem, should they not understand the signature they are seeing. More often than not, real failures in space are not anticipated or completely understood when first encountered. In the ammonia leak case discussed above, the failure that caused the signature was never anticipated. In fact, it was believed to be a failure mode that was not even credible or likely. Therefore, the team had to decipher the unusual signature in their data and figure out what to do in real time. An instructor, a senior flight controller in the group, or the student’s manager will evaluate each student through every phase. Several key areas are reviewed. One area is that of problem recognition. Identifying a failure and its impacts, especially within another system, can be difficult with complex systems and a large amount of data. Known failures have clear alarms, but what could have caused a box to fail may require some sleuthing. Other areas include mission cognizance (how the flight controller fits the failure into the bigger picture), communications, console management (how team members organize their data, logs, tools, and displays), and team interactions (either with other flight controllers or their own back room support). Even the student’s attitude is evaluated since someone who gets easily stressed or discouraged is not a good person to have on the team. After successfully completing the simulations and passing an evaluation by the flight director, the flight controller begins sitting on console under the watchful eye of an experienced operator in what is called on-the-job training. When the flight controller is considered ready, the “training wheels” are removed and he or she is certified as an operator—i.e., the first level of certification. That person can perform routine duties on console and respond in an emergency. For all systems except ETHOS, this generally means verifying that the software has reconfigured the systems automatically in response to the failure and then notifying an expert of the situation to obtain further direction. For ETHOS, the operator also supports the three big emergency responses on the ISS—fire, atmosphere leak, and toxic chemical spill—by leading the crew and flight control team through the associated procedures (see Chapter 19). For serious failures or complex operations, a more-senior controller (i.e., a specialist) who has undergone additional training and certification will support the console. Since training is so critical to the success of operations, the trainers (i.e., instructors) are part of the operations group and even support the console positions. This blending of operator/specialist/instructor ensures training is as accurate as possible. Once certified, flight controllers, instructors, and flight directors all must continue to perform proficiency training and evaluation to ensure they remain at peak performance levels. Flight directors are generally selected from seasoned flight controllers. As of December 2015, 91 individuals have been certified NASA flight directors. After all the generic training is complete, the controllers may be assigned to specific missions, such as an assembly mission (during the Space Shuttle era), a visiting vehicle (Soyuz or cargo flight), a software uplink, or a spacewalk. The assigned team will generally conduct flight- specific simulations in that unique timeline or activity. Complexity of the timeline determines the number of simulations, with the shuttle assembly missions having been on the high end with about a dozen, not counting numerous ascent and entry simulations with the crew. To illustrate the nature of this critical training, this chapter walks the reader through parts of a particular training session. The following is the transcript of real voice loop data in the Mission Control Center (MCC) recorded on April 24, 2013, during a generic simulation. Approximately 1 hour prior to the start of the event reflected in this transcript, the US Lab 1 Multiplexer/ DeMultiplexer (LA-1 MDM) experienced a failure such that it could no longer pass data to the Primary Command and Control MDM (see Chapter 5). Many impacts to the loss of communication to the LA-1 MDM occurred. A particularly important impact was that almost all insight into the performance of the LTL, which provided cooling to critical internal systems within the Laboratory Module, was lost (see Chapter 11). The Lab thermal system can be operated in dual mode or single loop. In dual mode, the LTL and the Moderate Temperature Loop (MTL) operate independently, each with its own pump. In single loop, the two segments are joined,
Purchased by unknown, nofirst nolast From: Scampersandbox (scampersandbox.tizrapublisher.com)